Hi! I have a TV logo image and a rect where the logo is placed on almost all video frames. But there are also frames where the logo completely disappears (at least 10 consecutive seconds of running frames). TV logo is placed only in only one place throughout the video (ROI = full logo rect), so I don't need to analyze full frame. How can I track when there is no logo in this area?
How can I track the disappearance of a TV logo in a certain area in a frame (ROI)?
↧
↧
historical performance test cast data in build pipeline?
Hi all. Is there organized data/results kept for *performance* tests that are automatically run/collected by the OpenCV build pipeline? So that I can inspect and compare across builds/releases performance changes? My intention is to see the performance effect of a code fix and compare it historically across all the platforms the pipeline/builtbot makes.
I can see at e.g. https://pullrequest.opencv.org/buildbot/builders/precommit_windows64/builds/27410/steps/perf_core that performance tests were run. The raw stdio was collected. That 44 seconds elapsed for 2400+ test cases. However, I do not see where the individual test results are collected, verified, or compared across builds. There is no visibility into how a single test within those 2400+ test cases in 44 seconds changes over time. Like `summary.py` does for isolated builds.
Naturally, I run performance tests on my own computers and I analyze individual test cases for changed code. But my tests run on a minority of the hardware/os platforms that the pipeline already does today. Which could lead to performance increasing on some platforms, and decreasing on others -- which is undesired.
↧
cv::dnn::blobFromImage() works in python but fails in c++
I am using opencv dnn.Net with the same network and with the same image in python and C++. While in python everything is ok, in C++ I get an access violation error from an opencv.dll.
Here is my code in python:
net = cv2.dnn.readNet(model, config, "Caffe")
input_img = cv2.imread(image_path)
blob = cv2.dnn.blobFromImage(input_img, 1.0, (40, 40), 0, False, False, cv2.CV_32F )
net.setInput(blob)
result = net.forward()
In this case no errors and I get the expected output.
Now the code in c++:
net = cv::dnn::readNet(model, config, "Caffe");
cv::Mat blob;
blob = cv::dnn::blobFromImage(input_image, 1.0, cv::Size(40,40), cv::Scalar(0,0,0), false, false, CV_32F);
net.setInput(blob);
net.forward();
In this case I get access violation as I run net.forward().
Both images are the same, and the are alreay 40x40, 3 channels. model and config are the same paths in python and c++ so the same caffe`model is being used.
Here is the error transcript in case this can be a hint:
> Exception thrown
> at 0x00007FFD2C1B12DE
> (vcruntime140.dll) in my_exe.exe:
> 0xC0000005: Access violation reading
> location 0x000001F972DB9000.
Why is the code failing in C++? How can I fix it?
↧
Triangulation with Ground Plane as Origin
Hello, I am working on a project where I have two calibrated cameras (c1, c2) mounted to the ceiling of my lab and I want to triangulate points on objects that I place in the capture volume. I want my final output 3D points to be relative to the world origin that is placed on the ground plane (floor of the lab). I have some questions about my process and multiplying the necessary transformations. Here is what I have done so far...
To start I have captured an image, with c1, of the ChArUco board on the ground that will act as the origin of my "world". I detect corners ( cv::aruco::detectMarkers/ cv::aruco::interpolateCornersCharuco) in the image taken by c1 and obtain the transformation (with cv::projectPoints) from 3D world coordinates to 3D camera coordinates.
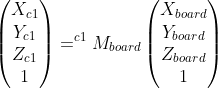
I followed the same process of detecting corners on the ChArUco board with c2 (board in same position) and obtained the transformation that takes a point relative to the board origin to the camera origin...
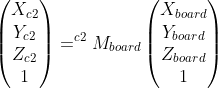
**Q1. With the two transformations, and my calibrated intrinsic parameters, should I be able to pass these to cv::triangulatePoints to obtain 3D points that are relative to the ChArUco board origin?**
Next, I was curious if I use cv::stereoCalibrate with my camera pair to obtain the transformation from camera 2 relative points to camera 1 relative points, could I combine this with the transform from camera 1 relative points to board relative points...to get a transform from camera 2 relative points to board relative points...
After running cv::stereoCalibrate I obtain (where c1 is the origin camera that c2 transforms to)...
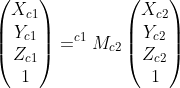
**Q2. Should I be able to combine transforms in the follow manner to get a transform that is the same (or very close) as my transform for board points to camera 2 points?**
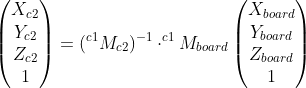
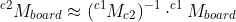
**I tried to do this and noticed that the transform obtained by detecting the ChArUco board corners is significantly different than the one obtained by combing the transformations. Should this work as I stated, or have I misunderstood something and done the math incorrectly? Here is output I get for the two methods (translation units are meters)...**
Output from projectPoints
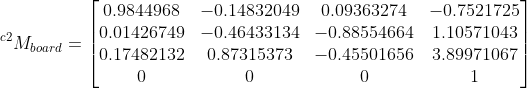
Output from combined transforms (projectPoints w/ c1 and board, and stereoCalibrate w/ c1 and c2)
↧
Error building opencv with extra modules in Visual Studio 2013
I have configured and generated opencv 4.5.0 with extra modules on CMAKE successfully. However, when building this project in Visual Studio I get several errors. Below, you could find: small sample of the errors>c:\users\mini\downloads\opencv-4.5.0\opencv-4.5.0\modules\core\include\opencv2\core\ocl.hpp(739): error C2610: 'cv::ocl::OpenCLExecutionContext::OpenCLExecutionContext(cv::ocl::OpenCLExecutionContext &&)' : n'est pas une fonction membre spéciale qui peut être définie par défaut
1>c:\users\mini\downloads\opencv-4.5.0\opencv-4.5.0\modules\core\include\opencv2\core\ocl.hpp(742): error C2610: 'cv::ocl::OpenCLExecutionContext &cv::ocl::OpenCLExecutionContext::operator =(cv::ocl::OpenCLExecutionContext &&)' : n'est pas une fonction membre spéciale qui peut être définie par défaut
2>C:\Users\Mini\Downloads\opencv-4.5.0\opencv-4.5.0\3rdparty\quirc\src\quirc.c(68): error C2275: 'size_t' : utilisation non
conforme de ce type comme expression
2> C:\Users\Mini\Downloads\opencv-4.5.0\opencv-4.5.0\3rdparty\quirc\src\quirc.c : voir la déclaration de 'size_t'
2>C:\Users\Mini\Downloads\opencv-4.5.0\opencv-4.5.0\3rdparty\quirc\src\decode.c(409): error C2054: '(' attendu après 'inline'
2>C:\Users\Mini\Downloads\opencv-4.5.0\opencv-4.5.0\3rdparty\quirc\src\quirc.c(68): error C2146: erreur de syntaxe : absence de ';' avant l'identificateur 'olddim'
2>C:\Users\Mini\Downloads\opencv-4.5.0\opencv-4.5.0\3rdparty\quirc\src\decode.c(410): error C2085: 'grid_bit' : ne figure pas dans la liste de paramètres formels
2>C:\Users\Mini\Downloads\opencv-4.5.0\opencv-4.5.0\3rdparty\quirc\src\quirc.c(68): error C2065: 'olddim' : identificateur non déclaré
2>C:\Users\Mini\Downloads\opencv-4.5.0\opencv-4.5.0\3rdparty\quirc\src\decode.c(410): error C2143: erreur de syntaxe : absence de ';' avant '{'
2>C:\Users\Mini\Downloads\opencv-4.5.0\opencv-4.5.0\3rdparty\quirc\src\quirc.c(70): error C2065: 'olddim' : identificateur non déclaré
2>C:\Users\Mini\Downloads\opencv-4.5.0\opencv-4.5.0\3rdparty\quirc\src\decode.c(427): warning C4013: 'grid_bit' non défini(e) ; extern retournant int pris par défaut
2>C:\Users\Mini\Downloads\opencv-4.5.0\opencv-4.5.0\3rdparty\quirc\src\decode.c(615): error C2054: '(' attendu après 'inline'
2>C:\Users\Mini\Downloads\opencv-4.5.0\opencv-4.5.0\3rdparty\quirc\src\decode.c(616): error C2085: 'bits_remaining' : ne figure pas dans la liste de paramètres formels
2>C:\Users\Mini\Downloads\opencv-4.5.0\opencv-4.5.0\3rdparty\quirc\src\decode.c(616): error C2143: erreur de syntaxe : absence de ';' avant '{'
2>C:\Users\Mini\Downloads\opencv-4.5.0\opencv-4.5.0\3rdparty\quirc\src\decode.c(646): warning C4013: 'bits_remaining' non défini(e) ; extern retournant int pris par défaut
3>------ Début de la génération : Projet : opencv_i
mgproc, Configuration : Release x64 ------
3> opencv_imgproc_pch.cpp
3>C:\Users\Mini\Downloads\opencv-4.5.0\opencv-4.5.0\modules\core\include\opencv2/core/ocl.hpp(739): error C2610: 'cv::ocl::OpenCLExecutionContext::OpenCLExecutionContext(cv::ocl::OpenCLExecutionContext &&)' : n'est pas une fonction membre spéciale qui peut être définie par défaut
3>C:\Users\Mini\Downloads\opencv-4.5.0\opencv-4.5.0\modules\core\include\opencv2/core/ocl.hpp(742): error C2610: 'cv::ocl::OpenCLExecutionContext &cv::ocl::OpenCLExecutionContext::operator =(cv::ocl::OpenCLExecutionContext &&)' : n'est pas une fonction membre spéciale qui peut être définie par défaut
19>C:\Users\Mini\Downloads\newbuild8\3rdparty\ade\ade-0.1.1f\sources\ade\include\ade/memory/memory_types.hpp(20):
error C2143: erreur de syntaxe : absence de ';' avant 'size_t' (C:\Users\Mini\Downloads\newbuild8\3rdparty\ade\ade-0.1.1f\sources\ade\source\memory_accessor.cpp)
19>C:\Users\Mini\Downloads\newbuild8\3rdparty\ade\ade-0.1.1f\sources\ade\include\ade/util/md_view.hpp(141): error C2780: 'ade::util::MemoryRange ade::util::slice(const ade::util::MemoryRange&,const size_t,const size_t)' : 3 arguments attendus - 2 fournis (C:\Users\Mini\Downloads\newbuild8\3rdparty\ade\ade-0.1.1f\sources\ade\source\memory_descriptor.cpp)
19> C:\Users\Mini\Downloads\newbuild8\3rdparty\ade\ade-0.1.1f\sources\ade\include\ade/util
/memory_range.hpp(220) : voir la déclaration de 'ade::util::slice'
19>C:\Users\Mini\Downloads\newbuild8\3rdparty\ade\ade-0.1.1f\sources\ade\include\ade/memory/memory_types.hpp(21): error C2975: 'MaxDimensions' : argument template non valide pour 'ade::util::DynMdSize', expression constante évaluée au moment de la compilation attendue (C:\Users\Mini\Downloads\newbuild8\3rdparty\ade\ade-0.1.1f\sources\ade\source\memory_accessor.cpp)
19> C:\Users\Mini\Downloads\newbuild8\3rdparty\ade\ade-0.1.1f\sources\ade\include\ade/util/md_size.hpp(26) : voir la déclaration de 'MaxDimensions'
19>C:\Users\Mini\Downloads\newbuild8\3rdparty\ade\ade-0.1.1f\sources\ade\include\ade/util/md_view.hpp(141): error
C2660: 'ade::util::details::mdview_copy_helper' : la fonction ne prend pas 3 arguments (C:\Users\Mini\Downloads\newbuild8\3rdparty\ade\ade-0.1.1f\sources\ade\source\memory_descriptor.cpp)
19>C:\Users\Mini\Downloads\newbuild8\3rdparty\ade\ade-0.1.1f\sources\ade\include\ade/memory/memory_types.hpp(22): error C2975: 'MaxDimensions' : argument template non valide pour 'ade::util::DynMdSpan', expression constante évaluée au moment de la compilation attendue (C:\Users\Mini\Downloads\newbuild8\3rdparty\ade\ade-0.1.1f\sources\ade\source\memory_accessor.cpp)
19> C:\Users\Mini\Downloads\newbuild8\3rdparty\ade\ade-0.1.1f\sources\ade\include\ade/util/md_span.hpp(63) : voir la déclaration de 'MaxDimensions'
19>C:\Users\Mini\Downloads\newbuil
d8\3rdparty\ade\ade-0.1.1f\sources\ade\include\ade/memory/memory_types.hpp(25): error C2975: 'MaxDimensions' : argument template non valide pour 'ade::util::DynMdView', expression constante évaluée au moment de la compilation attendue (C:\Users\Mini\Downloads\newbuild8\3rdparty\ade\ade-0.1.1f\sources\ade\source\memory_accessor.cpp)
↧
↧
Reading and Writing Videos: Python on GPU with CUDA - VideoCapture and VideoWriter
I'm trying to crop a video, using Python 3+, by reading it frame-by-frame and write certain frames to a new video.
I want to use GPU to speed up this process, as for a 1h video, it would take my CPU ~24h to complete.
My understanding is,
Reading a video using CPU:
```
vid = cv2.VideoCapture(vid_path)
fps = int(vid.get(cv2.CAP_PROP_FPS))
total_num_frames = int(vid.get(cv2.CAP_PROP_FRAME_COUNT))
frame_width = int(vid.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(vid.get(cv2.CAP_PROP_FRAME_HEIGHT))
```
Writing a video using CPU:
```
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
new_vid = cv2.VideoWriter(new_vid_path, fourcc, fps, (frame_width, frame_height))
```
Reading a frame on CPU, uploading & downloading it to/from GPU, then writing it using CPU:
```
ret, frame = vid.read()
gpu_frame = cv2.cuda_GpuMat()
gpu_frame.upload(frame)
frame = gpu_frame.download()
new_vid.write(frame)
```
Note: I know uploading and downloading here is useless, I wrote it to express how I think the syntax should be used.
Is there a way to do this all on GPU?
Or is there another more efficient way to accomplish my goal?
↧
Problem with building pose Mat from rotation and translation matrices
I have two images captured in the same space (scene), one with known pose. I need to calculate the pose of the second (query) image. I have obtained the relative camera pose using essential matrix. Now I am doing calculation of camera pose through the matrix multiplication ([here](https://answers.opencv.org/question/31421/opencv-3-essentialmatrix-and-recoverpose/) is a formula).
I try to build the 4x4 pose Mat from rotation and translation matrices. My code is following
Pose bestPose = poses[best_view_index];
Mat cameraMotionMat = bestPose.buildPoseMat();
cout (3, 3) = 1.0;
Earlier in code. Fora each view image:
Mat E = findEssentialMat(pts1, pts2, focal, pp, FM_RANSAC, F_DIST, F_CONF, mask);
// Read pose for view image
Mat R, t; //, mask;
recoverPose(E, pts1, pts2, R, t, focal, pp, mask);
Pose pose (R, t);
poses.push_back(pose);
Initially method bestPose.buildPoseMat() returns Mat of size (3, 4). I need to extend the Mat to size (4, 4) with row [0.0, 0.0, 0.0, 1.0] (zeros vector with 1 on the last position). Strangely I get following output when print out the resultant matrix
> [0.9107258520121255,
> 0.4129580377861768, 0.006639390377046724, 0.9039011699443721;
> 0.4129661348384583, -0.9107463665340377, 0.0001652925667582038, -0.4277340727282191;
> 0.006115059555925467, 0.002591307168000504, -0.9999779453436902, 0.002497598952195387;
> 0, 0.0078125, 0, 0]
Last row does not look like it should be: [0, 0.0078125, 0, 0] rather than [0.0, 0.0, 0.0, 1.0]. Is this implementation correct? What could a problems with this matrix?
↧
getting out of arguments
The problem i'm trying to build something around the openvc advanced stitching solver. (the lower level API).
However that asumes all is given in command line arguments, this is not practical for me.
Is there a way to provide inline code to add an image series ?
So without using command line arguments, I need this essentially for all arguments.
be able to do in psudo code
args.images = "c:\img\plan1 c:\imgplan2 c:\imgplan3"
↧
Optimizations on opencv hog implementation(interp_weight, gaussian)
Hello,
I'm trying to implement hog descriptor algorithm on FPGA. I will use pure(without using any library) C++ code to synthesize design with Vivado HLS. So, i need to know what is the general formula which includes interp_weight, gaussian coefficients. The related opencl code is as follows;
int dist_center_y = dist_y - 4 * (1 - 2 * cell_y);
int idx = (dist_center_y + 8) * 16 + (dist_center_x + 8);
float gaussian = gauss_w_lut[idx];
idx = (dist_y + 8) * 16 + (dist_x + 8);
float interp_weight = gauss_w_lut[256+idx];
hist[bin.x * 48] += gaussian * interp_weight * vote.x;
hist[bin.y * 48] += gaussian * interp_weight * vote.y;
Its hard for me to read this opencl code, because i am unfamiliar to this language.
Is there any paper or guide which explaines steps of opencv hog implementation? I should create a C++ code which is fully compatible with opencv.
↧
↧
tvec and coordinate systems q
The output of solvePnp tvec and rvec: is tvec in world coordinates? I am guessing it is b/c the chessboard calibration is in mm.
Second, what is tvec measuring from-to?
↧
errors when building opencv 4.5.0 wit extra modules using Mingw
please help!!!! I I am building opencv with extra modules for java using Mingw and cmake , and get some errors in the console what can be the reason !!!!

↧
I am creating web application for face recognition using python flask app. I am already create static dataset. I need the text box to enter the name of the person after that capture image and it will store in to the dataset.
#camera.py
import cv2
import os
import time
from flask import Response
from pathlib import Path
import uuid
from contextlib import contextmanager
from typing import Callable
face_cascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
ds_factor = 0.6
font = cv2.FONT_HERSHEY_SIMPLEX
datasets = "datasets"
class VideoCamera:
def __new__(cls, *args, **kwargs):
if getattr(cls, '_instance', False):
return cls._instance
cls._instance = super().__new__(cls, *args, **kwargs)
return cls._instance
def __init__(self):
if not hasattr(self, 'video'):
self.video = cv2.VideoCapture(0)
def get_frame(self) -> bytes:
success, image = self.video.read()
if not success:
return b''
output = image.copy()
cv2.rectangle(image, (400, 300), (800, 600), (255, 255, 255), 2)
cv2.addWeighted(image, 0.5, output, 1 - .5, 0, output)
cv2.resize(output, None, fx=ds_factor, fy=ds_factor, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(output, cv2.COLOR_BGR2GRAY)
roi = gray[300:600, 400:800] # ymin,ymax, xmin,xmax !
faces = face_cascade.detectMultiScale(
roi, scaleFactor=1.1,
minNeighbors=5,
minSize=(200, 200),
flags=cv2.CASCADE_SCALE_IMAGE)
for (x, y, w, h) in faces:
cv2.rectangle(output, (x + 400, y + 300), (x + 400 + w, y + 300 + h), (255, 0, 0), 3)
cv2.putText(output, 'Number of Faces : ' + str(len(faces)), (40, 40), font, 1, (255, 0, 0), 2)
break
ret, jpeg = cv2.imencode('.jpg', output)
return jpeg.tobytes()
def save_to_dataset(self) -> str:
data_set_size: int = 20
sub_folder = 'swetha'
(width, height) = (130, 100)
dst_dir = Path(__file__).parent / Path(f'{datasets}/{sub_folder}')
dst_dir.mkdir(parents=True, exist_ok=True)
num_of_files = len([_ for _ in dst_dir.glob('*.*')])
if num_of_files >= data_set_size:
return ""
for _ in range(data_set_size - num_of_files):
success, image = self.video.read()
output = image.copy()
cv2.rectangle(image, (400, 300), (800, 600), (255, 255, 255), 2)
cv2.addWeighted(image, 0.5, output, 1 - .5, 0, output)
cv2.resize(output, None, fx=ds_factor, fy=ds_factor, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(output, cv2.COLOR_BGR2GRAY)
roi = gray[300:600, 400:800] # ymin,ymax, xmin,xmax !
faces = face_cascade.detectMultiScale(
roi, scaleFactor=1.1,
minNeighbors=5,
minSize=(200, 200),
flags=cv2.CASCADE_SCALE_IMAGE)
for (x, y, w, h) in faces:
cv2.rectangle(output, (x + 400, y + 300), (x + 400 + w, y + 300 + h), (255, 0, 0), 3)
cv2.putText(output, 'Number of Faces : ' + str(len(faces)), (40, 40), font, 1, (255, 0, 0), 2)
face = gray[y + 300:y + 300 + h, x + 400:x + 400 + w]
face_resize = cv2.resize(face, (width, height))
cv2.imwrite(f'{dst_dir / Path(str(uuid.uuid4()))}.png', face_resize)
return f'{data_set_size} image captured.'
#app.py
from flask import Flask, render_template, Response, request, jsonify
from werkzeug.utils import secure_filename
from camera import VideoCamera
from facerecog import VideoCamera
import numpy as np
from os import path, getcwd
import pathlib
import json
import time
import cv2
import os
app = Flask(__name__)
@app.route('/')
def index():
timeNow = time.asctime(time.localtime(time.time()))
# temp, hum = getDHTdata()
templateData = {
'time': timeNow,
# 'temp': temp,
# 'hum': hum
}
return render_template('index.html', **templateData)
@app.route('/camera')
def cam():
timeNow = time.asctime(time.localtime(time.time()))
templateData = {
'time': timeNow
}
return render_template('camera.html', **templateData)
def gen(camera):
while True:
frame = camera.get_frame()
yield (b'--frame\r\n'
b'Content-Type: image/jpeg\r\n\r\n' + frame + b'\r\n\r\n')
@app.route('/video_feed')
def video_feed():
return Response(gen(VideoCamera()),
mimetype='multipart/x-mixed-replace; boundary=frame')
@app.route('/exec2')
def parse1():
response_data_collection = VideoCamera().save_to_dataset()
response_data_collection = "Done with Collecting Data" if response_data_collection else "you are already exist"
return render_template('camera.html', alert=response_data_collection)
@app.route('/facerecog')
def clock():
timeNow = time.asctime(time.localtime(time.time()))
templateData = {
'time': timeNow
}
return render_template('recognize.html', **templateData)
def gen(facerecog):
while True:
frame = facerecog.get_frame()
yield (b'--frame\r\n'
b'Content-Type: image/jpeg\r\n\r\n' + frame + b'\r\n\r\n')
@app.route('/feed')
def feed():
return Response(gen(VideoCamera()),
mimetype='multipart/x-mixed-replace; boundary=frame')
if __name__ == '__main__':
app.run(host='0.0.0.0', debug=True)
#index.html
![]() #camera.html
#camera.html
Add Face
%20%7D%7D)
Face Recognition System
Go To The Face Recognition!
Keep your face inside the box
{{ alert }}
{{ time }}
RETURN
↧
stitcher advanced api everything get wrapped arround
Hi, first i used the basic hihger level api, wich resulted in panorama pictures it worked
But as i wanted to do some more i went for the deeper api with contrib opencv (i want transform txt outputs)
i got it stitching however most of the times it bends the result a lot, while my series is a panorama alike image.
what should the options be for telling it just stitch it side by side ?
↧
↧
Darknet makefile error when opencv=1, ubuntu 18.04
Hi, when i did this command:
sudo apt install libopencv-dev
And then, at the makefile of darknet:
Opencv=1 (from opencv=0)
After pressing the `make` command
I get this:
makefile:176: recipe for target 'darknet' failed make: *** [darknet] error 1
when i do this: `pkg-config --modversion opencv`
3.4.13
What can i do to resolve this? Thank you.
↧
How to avoid potential noise after Canny?
I have a time averaged grayscale frame of a video:

I applied Canny edge detector to that frame, but sometimes there is noise like this:

I want to extract the area of a tv logo using boundingRect(), but it works wrong if there is noise. How can i avoid it?
↧
Lot of Delay with my RTSP cam with OpenCV on Python
Good evening everyone.
I have some concerns regarding a project that I am setting up.
Indeed, when I display a simple Rtsp video stream via OpenCv, I have no problems. Everything is fluid. However I am using an haarcascaded face detection code and I have a lot of latencies and frames loss when i use it in my code.
I am looking for some avenues to explore because I can't find solutions despite my research on the Net.
I tried to change my camera but the problem is the same.
Below is the code:
import numpy as np
import cv2
from threading import Thread
class Algo(Thread):
def __init__(self, frame):
Thread.__init__(self)
self.frame = frame
def run(self):
faces = face_cascade.detectMultiScale(gray, 1.3,5)
for (x,y,w,h) in faces:
cv2.rectangle(frame, (x,y), (x+y, y+h), (255,0,0), 2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = frame[y:y+h, x:x+w]
cap = cv2.VideoCapture('rtsp://[username]:[password]@[IP]:554/Streaming/Channels/1/')
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_alt.xml')
while(True):
# Capture frame-by-frame
cap.grab()
ret, frame = cap.retrieve()
# Our operations on the frame come here
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
thread_1 = Algo(frame)
thread_1.start()
thread_1.join()
# Display the resulting frame
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything done, release the capture
cap.release()
cv2.destroyAllWindows()
Regards,
Pinigseu
↧
Opencv and OAK on Mac with new chip M1
I was wondering if opencv works (or will work) on the new MacBook Pros (2020)? These new laptops have their own apple chips (not intel based). I am also curious if the OAK( Opencv AI Kit) coming on 2021 will be also compatible?
↧
↧
binary calibration pattern with XY recoverable features
Hi all
I think I've seen this before, but it is also possible that such a thing does not exist and that I'm mistaken.
I'm looking for a calibration pattern which looks like low resolution binary noise.
e.g. 64x64 pixels of {1,0} values
It's like a continuous AR marker
When a camera (or other projection) image is taken of the pattern, it is then possible to discover for each pixel in the camera the XY position within the pattern.
I.e. it's a type of static structured light.
I presume:
1. It's not actually noise, but is designed to be unique at each area (like an AR marker is unique per marker)
2. It might be possible to do something similar with using actual noise and SIFT/similar - but that doesn't sound optimal
It seems tat this is what is being used in the Project Northstar calibration:

I might be misunderstanding though
Thank you
Elliot
↧
recover pose scale
Is there a way to get a relative scale for the translation vector given from cv2.recoverpose().
e.g over 11 frames i get 10 different translation vectors, s(i) * t(i), 0
↧
How to find surfance orientation (relative to camera) from single depth image?
Supposing I have access to the image stream of a depth camera, and there is a flat surface (e.g. floor, tabletop, etc) within the camera's FoV at all times, how could one estimate the floor vertical and horizontal orientation (or better yet, the rotation matrix/vector) from the camera perspective?
I have access to the camera matrix, therefore I can select multiple points on the surface and reconstruct their 3D coordinates on the camera frame. But how do I use those coordinates to build a transformation matrix (mostly rotation, translation is irrelevant, I'd just need to orient my reference frame orthogonally with the surface)
My main limitation seems to be that I do not have the correspondent coordinates on the surface points (on object/external reference), therefore can't use cv::`estimateAffine3D` or `cv::findHomography` or `cv::solvePnP`.
I've tried to estimate the plane equation using cv::SVD, but resulting fit doesn't seem to be that precise and I am not aware how could I use the plane equation to find the affine transformation matrix.
↧
findCirclesGrid can't find sub-pattern with hollow insides
I'm trying to find a unique 2x2 hollow center sub-pattern inside a circle grid pattern. Using "detect", generates keypoints that indicate that the hollow circles are detected correctly, but the 2x2 pattern is not detected. Looking for a sub-pattern with full circles works.
The code could be boiled down to:
import numpy as np
import cv2
import matplotlib.pyplot as plt
orientation_grid_size = (2, 2)
params_orientaion = cv2.SimpleBlobDetector_Params()
params_orientaion.minArea = 200
params_orientaion.maxArea = 800
params_orientaion.minRepeatability = 1
params_orientaion.filterByColor = True
params_orientaion.blobColor = 255 # Detect only white centers
detector_orientation = cv2.SimpleBlobDetector_create(params_orientaion)
color_image = cv2.imread("1607961786.3423488.jpg")
color_image = cv2.cvtColor(color_image, cv2.COLOR_BGR2RGB)
status_orientation, grid_points_orientation = cv2.findCirclesGrid(color_image,
patternSize=orientation_grid_size,
flags=cv2.CALIB_CB_SYMMETRIC_GRID,
blobDetector=detector_orientation)
print(status_orientation)
keypoints = detector_orientation.detect(color_image)
im_with_keypoints = cv2.drawKeypoints(color_image, keypoints, np.array([]), (255, 0, 0),
cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
plt.imshow(im_with_keypoints)
plt.show(block=True)
The original image:

The image with the keypoints:

↧
↧
Removing translation from double camera facing the same direction
Hi all,
I have a project for Android with which I take an image from the main camera as well as the "depth camera". The only problem is that the actual sensors are placed few centimeters away from each other, thus producing a result as seen below
[![enter image description here][1]][1]
[1]: https://i.stack.imgur.com/DAIn3.jpg
In order to map each pixel of the depth image to the actual image, I found the following method on android developers forum:
> To transform a pixel coordinates between two cameras facing the same direction, first the source camera **CameraCharacteristics#LENS_DISTORTION** must be corrected for. Then the source camera **CameraCharacteristics#LENS_INTRINSIC_CALIBRATION** needs to be applied, followed by the **CameraCharacteristics#LENS_POSE_ROTATION** of the source camera, the translation of the source camera relative to the destination camera, the **CameraCharacteristics#LENS_POSE_ROTATION** of the destination camera, and finally the inverse of **CameraCharacteristics#LENS_INTRINSIC_CALIBRATION** of the destination camera. This obtains a radial-distortion-free coordinate in the destination camera pixel coordinates.
but I am not quite sure how to approach this with opencv.
↧
Videocapture RTSP cause very high cpu usage
i using OpenCV 3.4.12 VideoCapture in c++ with a simple read operation from a rtsp stream.
A test with a 640x360 resolution runs with very high CPU usage 40-64% on my linux box with an i7 CPU.
how can i reduce the CPU usage?
Thanks!
↧
How to get bird view image which is synthized four side images?(get AVM: around view monitoring)
Hi
I'm making avm(around view monitoring) image by getting four side images from four fisheye cameras.
This process has three parts:
1. calibrate fisheye image/video/streaming
2. get top view(bird view) image
3. get avm image by synthesizing four side images
I has completed 1 and 2 parts, but I'm in trouble doing third part.
I researched it and I found that it is may related to 'stitching' or 'numpy array'.
But I don't know how to do it although I read documentation.
+add) presentresult image
[C:\fakepath\AVM_test.png](/upfiles/1608130263293884.png)
code: (brought from github [Ahid-Naif/Around-View-Monitoring-AVM](https://github.com/Ahid-Naif/Around-View-Monitoring-AVM))
import cv2
import numpy as np
import imutils
from Camera.Undistortion import UndistortFisheye
from Camera.PerspectiveTransformation import EagleView
# from Camera.Stitcher import stitchTwoImages
import time
class avm:
def __init__(self):
self.__leftCamera = UndistortFisheye("left_Camera")
self.__rightCamera = UndistortFisheye("right_Camera")
self.__leftEagle = EagleView()
self.__rightEagle = EagleView()
# self.__frontEagle.setDimensions((149, 195), (439, 207), (528, 380), (37, 374))
# self.__backEagle.setDimensions((164, 229), (469, 229), (588, 430), (45, 435))
#reset left/right setDimensions
self.__leftEagle.setDimensions((186, 195), (484, 207), (588, 402), (97, 363))
self.__rightEagle.setDimensions((171, 240), (469, 240), (603, 452), (52, 441))
# self.__leftEagle.setDimensions((186, 195), (484, 207), (588, 402), (97, 363))
# self.__rightEagle.setDimensions((171, 240), (469, 240), (603, 452), (52, 441))
self.__middleView = None
self.__counter = 0
# self.stitcher = stitchTwoImages("Bottom2Upper")
# self.upper = None
# self.bottom = None
def runAVM(self, leftFrame, rightFrame):
leftView = self.__leftCamera.undistort(leftFrame)
topDown_left = self.__leftEagle.transfrom(leftView)
rightView = self.__rightCamera.undistort(rightFrame)
topDown_right = self.__rightEagle.transfrom(rightView)
# topDown_Back = cv2.flip(topDown_Back, 1) #flip left/right
topDown_left , topDown_right = self.__reScale(topDown_left, topDown_right)
# stitchingResult = self.__startStitching(topDown_Front)
middleView = self.__getMiddleView(topDown_left)
birdView = np.hstack((topDown_left, middleView, topDown_right))
return birdView
def __reScale(self, topDown_left, topDown_right):
width_leftView = topDown_left.shape[1]
width_rightView = topDown_right.shape[1]
height_leftView = topDown_left.shape[0]
height_rightView = topDown_right.shape[0]
if height_leftView > height_rightView:
newHeight = height_rightView
ratio = height_rightView/height_leftView
newWidth = int(ratio * width_leftView)
topDown_left = cv2.resize(topDown_left, (newWidth, newHeight))
else:
newHeight = height_leftView
ratio = height_leftView/height_rightView
newWidth = int(ratio * width_rightView)
topDown_right = cv2.resize(topDown_right, (newWidth, newHeight))
return topDown_left, topDown_right
def __getMiddleView(self, topDown_left):
# the length of the image represents the distance in front or back of the car
width_leftView = topDown_left.shape[1]
if self.__middleView is None:
realWidth_leftView = 13 # unit is cm
realWidth_MiddleView = 29.5 # unit is cm
ratio = int(width_leftView/realWidth_leftView)
width_MiddleView = int(realWidth_MiddleView * ratio)
height_MiddleView = int(topDown_left.shape[0])
self.__middleView = np.zeros((height_MiddleView, width_MiddleView//2, 3), np.uint8)
# print(ratio)
# else:
# # self.__middleView[0:stitchingResult.shape[0], :]
return self.__middleView
# def __startStitching(self, accView):
# if self.bottom is None:
# self.bottom = accView
# return None
# else:
# # time.sleep(0.5)
# self.upper = accView
# self.bottom = self.stitcher.stitch(self.bottom, self.upper)
# cv2.imshow("Result", self.bottom)
# height = accView.shape[0]
# return self.bottom[height:self.bottom.shape[0], :]
If you know anythings about it, please comment and share your thoughts.
Thank you for your reading.
(I'm using opencv, python, raspberrypi 4B)
↧
Problem with undistortPoints() function in pose estimation of image
I have written about my task [here](https://answers.opencv.org/question/238792/problem-with-building-pose-mat-from-rotation-and-translation-matrices/). I have
a set of images with known pose which were used for scene reconstruction and some query image from the same space without pose. I need to calculate the pose of the query image. I solved this problem using essential matrix. Here is a code
Mat E = findEssentialMat(pts1, pts2, focal, pp, FM_RANSAC, F_DIST, F_CONF, mask);
// Read pose for view image
Mat R, t; //, mask;
recoverPose(E, pts1, pts2, R, t, focal, pp, mask);
The only problem is that OpenCv documentation [states](https://docs.opencv.org/3.4/d9/d0c/group__calib3d.html#ga13f7e34de8fa516a686a56af1196247f) that the findEssentialMat function assumes that points1 and points2 are feature points from cameras with the same camera intrinsic matrix. That's not a case for us - images of scene and query image can be captured by cameras with different intrinsics.
I suppose to use this undistortPoints() function. According to [documentation](https://docs.opencv.org/3.4/da/d54/group__imgproc__transform.html#ga55c716492470bfe86b0ee9bf3a1f0f7e) the undistortPoints() function takes two important parameters distCoeffs and cameraMatrix.
Both images of the scene and query image have calibration parameters associated (fx, fy, cx, cy).
I obtain cameraMatrix parameter this way:
Mat K_v = (Mat_(3, 3)
↧
↧
LineSegmentDetector
I need to show lines, but I have error this code:
QImage temp = nPixDst->pixmap().toImage();
Mat image = QImage2Mat( temp ) ;
cvtColor(image, image, COLOR_BGR2GRAY);
Canny(image, image, 50, 150, 3);
Ptr ls = createLineSegmentDetector(LSD_REFINE_NONE);
vector lines_std;
// Detect the lines
ls->detect(image, lines_std);
image = Scalar(0, 0, 0);
ls->drawSegments(image, lines_std);
nPixDst->setPixmap( QPixmap::fromImage( Mat2QImage( image )) );

could you help me, please?
↧
deletion of useless posts
according to [previous discussion](https://github.com/opencv-infrastructure/answers.opencv.org/issues/45) some questions already deleted and there are [many question like tagged "deleted"](https://answers.opencv.org/questions/scope:all/sort:activity-desc/tags:deleted/page:1/) waiting to be deleted.
**Deleted questions are still in the database of forum and can be recovered if needed.**
this is not an easy process, especially it is hard to decide if the question is really do not worth to have an answer.
i have some suggestions related this issue.
**1**. In my opinion upvoting any new question worth to have an answer and downvoting otherwise. yes some users and moderators do that but it will be great if all members who read the question use their vote.
**2**.we can leave a comment "voted for deleting"
**3**.All member can use `flag offensive` for useless posts
**4**. etc ( Please leave a comment or answer if you have more ideas )
***i will update this question frequently to be read by more users so some general messages about the forum is also welcome***
Sep 20 2020 total : 33,544 questions unanswered : 17,559 questions
Sep 22 2020 total : 33,500 questions unanswered : 17,500 questions
Sep 27 2020 total : 33,374 questions unanswered : 17,250 questions
Oct 1 2020 total : 32,996 questions unanswered : 16,791 questions
Oct 5 2020 total : 32,696 questions unanswered : 16,415 questions
Oct 8 2020 total : 32,448 questions unanswered : 16,000 questions
Oct 14 2020 total : 31,991 questions unanswered : 15,332 questions
Oct 16 2020 total : 31,900 questions unanswered : 15,200 questions
Oct 23 2020 total : 31,600 questions unanswered : 14,750 questions
Nov 13 2020 total : 30,800 questions unanswered : 13,700 questions
Dec 20 2020 total : 29,907 questions unanswered : 12,420 questions
↧
HSV white color range in JS
I would like to track white color using webcam and Opencv.js.
[Here](https://stackoverflow.com/questions/22588146/tracking-white-color-using-python-opencv) is the question/answer with python. I want to do exactly the same with **javascript** and tried this
const hsv = new cv.Mat();
cv.cvtColor(initialImage, hsv, cv.COLOR_BGR2HSV)
const lower_white = [0, 0, 0];
const upper_white = [0, 0, 255];
const low = new cv.Mat(hsv.rows, hsv.cols, hsv.type(), lower_white);
const high = new cv.Mat(hsv.rows, hsv.cols, hsv.type(), upper_white);
const dst = new cv.Mat();
cv.inRange(hsv, low, high, dst);
But it doesn't work. I'm getting the following error
Uncaught TypeError: Incorrect number of tuple elements for Scalar: expected=4, actual=3
Error is occurring on this line
const low = new cv.Mat(hsv.rows, hsv.cols, hsv.type(), lower_white);
The problem is that it wants lower_white array to have 4 elements instead of 3.
**What is the 4th element in HSV format?**
I also tried to put the 4th element from 0 to 255
const lower_white = [0, 0, 0, 0];
const upper_white = [0, 0, 255, 255];
In this case, there is no error but it doesn't seem right. It doesn't work.
**Any suggestions or explanations of what should be lower_white and upper_white values?**
↧
How can I check if the monitor is connected in Windows / Linux?
How can I check if the monitor is connected in Windows / Linux?
The following program behavior is required, when I run my application:
- if monitor is connected, then results will be showed in the window
- if monitor isn't connected, or if I run application by SSH, then results will be saved to the image.jpg
Currently, if monitor isn't connected or if I run my application by using SSH, I get an error, that I can't catch as exception:
> QXcbConnection: Could not connect to> display
#include
#include
#include
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
if( argc != 2) return -1;
Mat image = imread(argv[1], CV_LOAD_IMAGE_COLOR);
if(! image.data ) return -1;
try {
namedWindow( "Display window", WINDOW_AUTOSIZE );
imshow( "Display window", image );
waitKey(0);
} catch(...) {
imwrite( "output.jpg", image );
}
return 0;
}
Currently OpenCV application requires addition flag -monitor to enable/disable output to the window, that isn't very usable.
There is not required a full-fledged API, which would replace the OS API. But it would be very useful if there was a function that returns whether the monitor is connected or not.
↧
↧
Opencv for pcb parts detection and angle calculation
Hi,
I’m new in Opencv .
I want to detect pcb parts (Es. capactors, resistors etc.) with opencv and calculate current rotation angle.
There is an easy and optimized way to do this ?
↧
More Pages to Explore .....







