Hello,
**Short story:**
Can anyone describe the process of how to use OpenCV in a C++ Project for Android in Visual Studio?
----------
**Long story**:
I'm currently trying to build an OpenCV native plugin for Unity using Visual Studio. As it should be as platform independent as possible (except Linux), it's necessary to build the DLL for Windows, Android etc. That's also the reason why I'd prefer to stick to Visual Studio instead of Android Studio as it's (theoretically) possible to develop for all of those platforms there.
I already managed to setup OpenCV for UWP and Windows, however, I don't really know how to do this for Android. I already created a Visual Studio Cross-Platform C++ Project that Outputs a dynamic library (.so). It's compiling as long as I don't do anything OpenCV related in there.
My first try was to just use the normal OpenCV library for C++, but it gives me errors like *"cannot use throw with exceptions disabled"* and a lot more.
As a next step, I downloaded the OpenCV4Android .zip from the releases page and unzipped it. I added *"OpenCV-android-sdk\sdk\native\jni\include"* as additional include directory and *"\OpenCV-android-sdk\sdk\native\libs\PLATFORM"* as additional library directory, where *"PLATFORM"* is the build configuration (x64, x86, amd, etc.).
I then added "libopencv_core.a" to additional dependencies and tried to compile the whole thing, however, it says "There is no such file or directory: libopencv_core.a". If I remove it from the additional dependencies, it says *"Linker command failed with exit code -1".*
Also, I get a lot of errors saying *"builtin function is not available because vector types are not supported"*.
↧
How to build OpenCV for Android using Visual Studio?
↧
Overhead camera's pose estimation with OpenCV SolvePnP results in a few centimeter off height
I'd like to get the pose (translation: x, y, z and rotation: Rx, Ry, Rz in World coordinate system) of the overhead camera. I got many object points and image points by moving the ChArUco calibration board with a robotic arm (like this https://www.youtube.com/watch?v=8q99dUPYCPs). Because of that, I already have exact positions of all the object points.
In order to feed many points to `solvePnP`, I set the first detected pattern (ChArUco board) as the first object and used it as the object coordinate system's origin. Then, I added the detected object points (from the second pattern to the last) to the first detected object points' coordinate system (the origin of the object frame is the origin of the first object).
After I got the transformation between the camera and the object's coordinate frame, I calculated the camera's pose based on that transformation.
The result looked pretty good at first, but when I measured the camera's absolute pose by using a ruler or a tape measure, I noticed that **the extrinsic calibration result was around 15-20 millimeter off for z direction (the height of the camera)**, though almost correct for the others (x, y, Rx, Ry, Rz). The result was same even I changed the range of the object points by moving a robotic arm differently, it always ended up to have a few centimeters off for the height.
Has anyone experienced the similar problem before? I'd like to know anything I can try. What is the common mistake when the depth direction (z) is inaccurate?
↧
↧
How do I draw a scale inside the bounding box?
I want to measure the dimension of the objects in a image.
`This is my original image`

`These are bounding box that I have drawn around the detected objects`

As can be seen even the `shadow` is being detected as `area under the interested object`.
Unfortunately, I doubt manipulating the image in any way can help me minimise the error in me detecting a wrong dimension.
I would like to draw draw small lines inside on two sides of the bounding box as can seen on the ruler image below

Which definitely will help me get a accurate measurement without manipulating the original image in any way
Can any suggestion how this can be done?
↧
Why is the Charuco Board Calibration so much better against a flipping Z-Axis then the normal OpenCV chessboard?
Hi Together,
I have many problems with a flipping Z-Axis on my ArUco Markers when I used the normal OpenCV chessboard. Since I used the CharUco Board to calibrate my camera, I have nearly no flipping axis anymore. But I have no idea why it is so much better? For sure it is much more accurate but in which way does this affect the flipping axis?
Thank you for every answer :)
Sarah
↧
I get all features 0, i.e., hist in my example program are all 0.0
import cv2
image = cv2.imread("D:\\skhan\\research\\data\\face\\test.2.jpg",cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
winSize = (64,64)
blockSize = (16,16)
blockStride = (8,8)
cellSize = (8,8)
nbins = 9
derivAperture = 1
winSigma = 4.0
histogramNormType = 0
L2HysThreshold = 2.0000000000000001e-01
gammaCorrection = 0
nlevels = 64
hog=cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nbins,derivAperture,winSigma,histogramNormType,L2HysThreshold,gammaCorrection,nlevels)
winStride = (8,8)
padding = (8,8)
locations = ((10,20),)
hist = hog.compute(image,winStride,padding,locations)
image = cv2.imread("D:\\skhan\\research\\data\\face\\test.2.jpg",cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
winSize = (64,64)
blockSize = (16,16)
blockStride = (8,8)
cellSize = (8,8)
nbins = 9
derivAperture = 1
winSigma = 4.0
histogramNormType = 0
L2HysThreshold = 2.0000000000000001e-01
gammaCorrection = 0
nlevels = 64
hog=cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nbins,derivAperture,winSigma,histogramNormType,L2HysThreshold,gammaCorrection,nlevels)
winStride = (8,8)
padding = (8,8)
locations = ((10,20),)
hist = hog.compute(image,winStride,padding,locations)
↧
↧
opencv configure using cmake::error
when i am compiling cmake to my ubuntu i face this issue
/usr/bin/ld: warning: libprotobuf.so.15, needed by ../../lib/libopencv_dnn.so.3.1.0, not found (try using -rpath or -rpath-link)
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::RegisterAllTypes(google::protobuf::Metadata const*, int)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::Refresh()'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::WriteUInt32(int, unsigned int, google::protobuf::io::CodedOutputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedOutputStream::WriteStringWithSizeToArray(std::__cxx11::basic_string, std::allocator> const&, unsigned char*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::FieldDescriptor::TypeOnceInit(google::protobuf::FieldDescriptor const*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::Arena::OnArenaAllocation(std::type_info const*, unsigned long) const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::WriteEnum(int, int, google::protobuf::io::CodedOutputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::WriteStringMaybeAliased(int, std::__cxx11::basic_string, std::allocator> const&, google::protobuf::io::CodedOutputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::ReadVarintSizeAsIntFallback()'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `vtable for google::protobuf::io::IstreamInputStream'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::InitProtobufDefaults()'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::WriteInt32(int, int, google::protobuf::io::CodedOutputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::Message::CheckTypeAndMergeFrom(google::protobuf::MessageLite const&)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::ReadVarint64Fallback()'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::GoogleOnceInitImpl(long*, google::protobuf::Closure*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::ReadTagFallback(unsigned int)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::UInt32Size(google::protobuf::RepeatedField const&)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `typeinfo for google::protobuf::Closure'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::RepeatedField const& google::protobuf::Reflection::GetRepeatedField(google::protobuf::Message const&, google::protobuf::FieldDescriptor const*) const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::fixed_address_empty_string[abi:cxx11]'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::ReadBytes(google::protobuf::io::CodedInputStream*, std::__cxx11::basic_string, std::allocator>*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::Message::GetTypeName[abi:cxx11]() const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedOutputStream::WriteVarint32SlowPath(unsigned int)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedOutputStream::WriteVarint64SlowPath(unsigned long)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::ArenaImpl::AllocateAlignedAndAddCleanup(unsigned long, void (*)(void*))'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::Message::InitializationErrorString[abi:cxx11]() const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::WriteFloat(int, float, google::protobuf::io::CodedOutputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::MessageLite::ParseFromCodedStream(google::protobuf::io::CodedInputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormat::SerializeUnknownFields(google::protobuf::UnknownFieldSet const&, google::protobuf::io::CodedOutputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::Message::DiscardUnknownFields()'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::RepeatedField const& google::protobuf::Reflection::GetRepeatedField(google::protobuf::Message const&, google::protobuf::FieldDescriptor const*) const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::BytesUntilLimit() const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::ArenaImpl::AllocateAligned(unsigned long)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::UnknownFieldSet::AddVarint(int, unsigned long)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::Closure::~Closure()'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::BytesUntilTotalBytesLimit() const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::ReadLittleEndian32Fallback(unsigned int*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::ArenaImpl::AddCleanup(void*, void (*)(void*))'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::WriteBool(int, bool, google::protobuf::io::CodedOutputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::MessageLite::SerializeWithCachedSizesToArray(unsigned char*) const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::WriteMessageMaybeToArray(int, google::protobuf::MessageLite const&, google::protobuf::io::CodedOutputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::RepeatedPtrFieldBase::Reserve(int)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::WriteInt64(int, long, google::protobuf::io::CodedOutputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::OnShutdownDestroyMessage(void const*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `vtable for google::protobuf::internal::FunctionClosure0'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::WriteFloatArray(float const*, int, google::protobuf::io::CodedOutputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::DescriptorPool::InternalAddGeneratedFile(void const*, int)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::ReflectionOps::Merge(google::protobuf::Message const&, google::protobuf::Message*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::FieldDescriptor::kTypeToName'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::IstreamInputStream::IstreamInputStream(std::istream*, int)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CopyingInputStreamAdaptor::~CopyingInputStreamAdaptor()'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::FunctionClosure0::~FunctionClosure0()'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::TextFormat::Parse(google::protobuf::io::ZeroCopyInputStream*, google::protobuf::Message*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `typeinfo for google::protobuf::Message'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::OnShutdownDestroyString(std::__cxx11::basic_string, std::allocator> const*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::WriteString(int, std::__cxx11::basic_string, std::allocator> const&, google::protobuf::io::CodedOutputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::VerifyVersion(int, int, char const*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::Reflection::MutableRawRepeatedString(google::protobuf::Message*, google::protobuf::FieldDescriptor const*, bool) const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::Int32Size(google::protobuf::RepeatedField const&)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::PushLimit(int)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::UnknownFieldSet::MergeFrom(google::protobuf::UnknownFieldSet const&)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::SetTotalBytesLimit(int, int)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::RepeatedField const& google::protobuf::Reflection::GetRepeatedField(google::protobuf::Message const&, google::protobuf::FieldDescriptor const*) const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::RepeatedField const& google::protobuf::Reflection::GetRepeatedField(google::protobuf::Message const&, google::protobuf::FieldDescriptor const*) const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::ReadRaw(void*, int)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::UnknownFieldSet::ClearFallback()'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::~CodedInputStream()'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::IncrementRecursionDepthAndPushLimit(int)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormat::SerializeUnknownFieldsToArray(google::protobuf::UnknownFieldSet const&, unsigned char*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormat::ComputeUnknownFieldsSize(google::protobuf::UnknownFieldSet const&)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::Message::SpaceUsedLong() const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::RepeatedField const& google::protobuf::Reflection::GetRepeatedField(google::protobuf::Message const&, google::protobuf::FieldDescriptor const*) const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::IstreamInputStream::CopyingIstreamInputStream::~CopyingIstreamInputStream()'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::ReadVarint32Fallback(unsigned int)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::PopLimit(int)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::RepeatedPtrFieldBase::InternalExtend(int)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormat::SkipField(google::protobuf::io::CodedInputStream*, unsigned int, google::protobuf::UnknownFieldSet*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::RepeatedField const& google::protobuf::Reflection::GetRepeatedField(google::protobuf::Message const&, google::protobuf::FieldDescriptor const*) const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::FieldDescriptor::kTypeToCppTypeMap'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::MessageFactory::InternalRegisterGeneratedFile(char const*, void (*)(std::__cxx11::basic_string, std::allocator> const&))'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::SkipFallback(int, int)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormatLite::WriteBytesMaybeAliased(int, std::__cxx11::basic_string, std::allocator> const&, google::protobuf::io::CodedOutputStream*)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::AssignDescriptors(std::__cxx11::basic_string, std::allocator> const&, google::protobuf::internal::MigrationSchema const*, google::protobuf::Message const* const*, unsigned int const*, google::protobuf::MessageFactory*, google::protobuf::Metadata*, google::protobuf::EnumDescriptor const**, google::protobuf::ServiceDescriptor const**)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::DecrementRecursionDepthAndPopLimit(int)'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::RepeatedField const& google::protobuf::Reflection::GetRepeatedField(google::protobuf::Message const&, google::protobuf::FieldDescriptor const*) const'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::io::CodedInputStream::default_recursion_limit_'
../../lib/libopencv_dnn.so.3.1.0: undefined reference to `google::protobuf::internal::WireFormat::ReadPackedEnumPreserveUnknowns(google::protobuf::io::CodedInputStream*, unsigned int, bool (*)(int), google::protobuf::UnknownFieldSet*, google::protobuf::RepeatedField*)'
collect2: error: ld returned 1 exit status
modules/dnn/CMakeFiles/example_dnn_caffe_googlenet.dir/build.make:100: recipe for target 'bin/example_dnn_caffe_googlenet' failed
make[2]: *** [bin/example_dnn_caffe_googlenet] Error 1
CMakeFiles/Makefile2:5181: recipe for target 'modules/dnn/CMakeFiles/example_dnn_caffe_googlenet.dir/all' failed
make[1]: *** [modules/dnn/CMakeFiles/example_dnn_caffe_googlenet.dir/all] Error 2
make[1]: *** Waiting for unfinished jobs....
↧
wrong rotation matrix when using recoverpose between two very similar images
I'm trying to perform visual odometry with a camera on top of a car. Basically I use Fast or GoodFeaturesToTrack ( I don't know yet which one is more convenient) and then I follow those points with calcOpticalFlowPyrLK. Once I have both previuos and actual points I call findEssentialMat and then recoverPose to obtain rotation and translation matrix.
My program works quite well. It has some errors when there are images with sun/shadow in the sides but the huge problem is WHEN THE CAR STOPS. When the car stops or his speed is quite low the frames looks very similar (or nearly the same) and the rotation matrix gets crazy (I guess the essential matrix too).
Does anyone knows if it is a common error? Any ideas on how to fix it?
I don't know what information you need to answer it but it seems that It is a concept mistake that I have. I have achieved an acurracy of 1º and 10 metres after a 3km ride but anytime I stop.....goodbye!
Thank you so much in advance
↧
recoverpose
Just a simple question, in these two statements
E = cv::findEssentialMat(
points1, points2, focal, pp, cv::RANSAC, 0.999, 1.0, mask);
cv::recoverPose(E, points1, points2, R, t, focal, pp, mask);
Is the rotation and translation calculated from points1 to points2 or points2 to points1?
Thank you.
↧
[HELP]LCD screen extraction from an image with opencv and python
I am a beginner in opencv and image processing. I am following official python documentation for learning.
I am trying to extract the three LCD screen from [this](https://imgur.com/DK7DPZZ) image and eventually recognize digits from them. For this I am following this [pyimagesearch article](https://www.pyimagesearch.com/2017/02/13/recognizing-digits-with-opencv-and-python/).
But I can't generate a smooth rectangle edge around the LCDs through canny edge detection algorithm. So I am failing in generating rectangle contours and extracting LCDs. I have tried different values for min and max parameters. [Here is what I get at most](https://imgur.com/vlH3yXm). Now I am stuck! Here is my [code](https://gist.github.com/aagontuk/3ea00a9a07829a03bfae2ab0d2130558).
Can I do better? How can I improve this? What things should I consider?
Thanks!
↧
↧
Hello, currently i am using open CV with .NET(C#) for face detection,i want to do face detection web application(Asp.NET MVC), is it possible to make web application using "OPENCV"?
Hello, currently i am using open CV with .NET(C#) for face detection, I already completed windows application(winform) using C#.NET with emgu libraries, Now i want to do the same thing as a web application(Asp.NET MVC), is it possible to make web application using "OPENCV"?
↧
Chromatic Surface
I am working on a project that involves removing highlight areas of an image. I stumbled on the paper; [Real-time Specular Highlight Removal Using Bilateral Filtering](http://vision.ai.illinois.edu/publications/eccv-10-qingxiong-yang.pdf), which has shown some promising results. For it to work though, they require
> the input images have chromatic
> surfaces
My questions are:
1. What is a chromatic surface? Taking a guess from the input images shown in the paper, they all share a dark background. Is this what a chromatic surface is? Just an image with a dark background? Does the object have to be up-close?
2. Given your standard BGR input image, is it possible to convert it to the required standard i.e. chromatic surface? If yes, how?
The second question might sound stupid but that is because I have zero knowledge of what a chromatic surface is in the first place. Any guidance will greatly appreciated
↧
Extract google map embedded from an image
Assume, if I have an address image from a user, which has "textual" details of address e.g Street name, City etc.
Along with the textual details, image also contains a "map" embedded in it.
e.g see image : 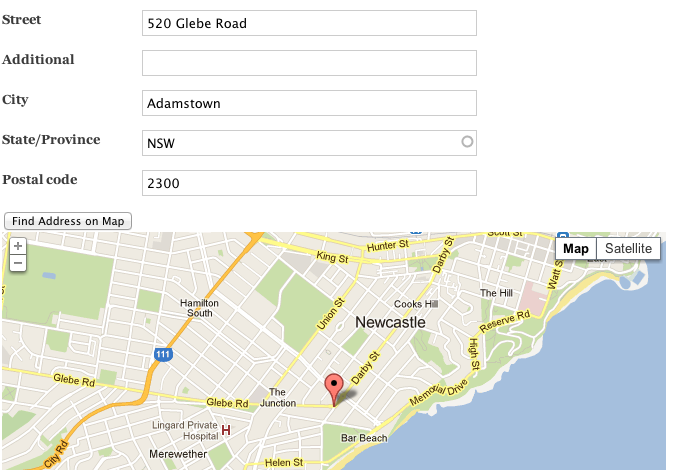.
Now I have to predict, if the image has a map in it or not. My questions
1) What are the features, that shall be trained for images of "map"
2) Can I identify and extract the map contour from the image attached.
↧
opencv3.0 videowriter can't open encoder
when I use Videocapture of opencv2.x to save a video like
video = VideoWriter("camera.avi", CV_FOURCC('X', 'V', 'I', 'D'), 32, cvSize(int(capture.get(CV_CAP_PROP_FRAME_WIDTH)), int(capture.get(CV_CAP_PROP_FRAME_HEIGHT))));
it is ok to open xvid encoder ,but when i use opencv3.0 xvid encoder is not open at all, I don't kown how to sovle this
problem ,please help
!!!!!
↧
↧
How to determine length of spline (e.g. snake)

Hello,
I'm trying to automatically determine length of a spline - well, in this case it's the length of a snake. I thought I could modify existing code and then divide the contour into segments but I'm not having much luck.
The black rectangle in the photo is 12" x 2". The snake is more than 5' long.
Can someone point me in the right direction?
Command line used:
python object_size.py --image images/img_1718_useforcalib_w2.5.jpg --width 2.5
Code:
# USAGE
# python object_size.py --image images/example_01.png --width 0.955
# python object_size.py --image images/example_02.png --width 0.955
# python object_size.py --image images/example_03.png --width 3.5
# import the necessary packages
from scipy.spatial import distance as dist
from imutils import perspective
from imutils import contours
import numpy as np
import argparse
import imutils
import cv2
def midpoint(ptA, ptB):
return ((ptA[0] + ptB[0]) * 0.5, (ptA[1] + ptB[1]) * 0.5)
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-w", "--width", type=float, required=True,
help="width of the left-most object in the image (in inches)")
args = vars(ap.parse_args())
# load the image, convert it to grayscale, and blur it slightly
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (7, 7), 0)
# perform edge detection, then perform a dilation + erosion to
# close gaps in between object edges
edged = cv2.Canny(gray, 50, 100)
edged = cv2.dilate(edged, None, iterations=1)
edged = cv2.erode(edged, None, iterations=1)
# find contours in the edge map
cnts = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if imutils.is_cv2() else cnts[1]
# sort the contours from left-to-right and initialize the
# 'pixels per metric' calibration variable
(cnts, _) = contours.sort_contours(cnts)
pixelsPerMetric = None
# loop over the contours individually
for c in cnts:
# if the contour is not sufficiently large, ignore it
if cv2.contourArea(c) < 100:
continue
# compute the rotated bounding box of the contour
orig = image.copy()
box = cv2.minAreaRect(c)
box = cv2.cv.BoxPoints(box) if imutils.is_cv2() else cv2.boxPoints(box)
box = np.array(box, dtype="int")
# order the points in the contour such that they appear
# in top-left, top-right, bottom-right, and bottom-left
# order, then draw the outline of the rotated bounding
# box
box = perspective.order_points(box)
cv2.drawContours(orig, [box.astype("int")], -1, (0, 255, 0), 2)
# loop over the original points and draw them
for (x, y) in box:
cv2.circle(orig, (int(x), int(y)), 5, (0, 0, 255), -1)
# unpack the ordered bounding box, len compute the midpoint
# between the top-left and top-right coordinates, followed by
# the midpoint between bottom-left and bottom-right coordinates
(tl, tr, br, bl) = box
(tltrX, tltrY) = midpoint(tl, tr)
(blbrX, blbrY) = midpoint(bl, br)
# compute the midpoint between the top-left and top-right points,
# followed by the midpoint between the top-righ and bottom-right
(tlblX, tlblY) = midpoint(tl, bl)
(trbrX, trbrY) = midpoint(tr, br)
# draw the midpoints on the image
cv2.circle(orig, (int(tltrX), int(tltrY)), 5, (255, 0, 0), -1)
cv2.circle(orig, (int(blbrX), int(blbrY)), 5, (255, 0, 0), -1)
cv2.circle(orig, (int(tlblX), int(tlblY)), 5, (255, 0, 0), -1)
cv2.circle(orig, (int(trbrX), int(trbrY)), 5, (255, 0, 0), -1)
# draw lines between the midpoints
cv2.line(orig, (int(tltrX), int(tltrY)), (int(blbrX), int(blbrY)),
(255, 0, 255), 2)
cv2.line(orig, (int(tlblX), int(tlblY)), (int(trbrX), int(trbrY)),
(255, 0, 255), 2)
# compute the Euclidean distance between the midpoints
dA = dist.euclidean((tltrX, tltrY), (blbrX, blbrY))
dB = dist.euclidean((tlblX, tlblY), (trbrX, trbrY))
# if the pixels per metric has not been initialized, then
# compute it as the ratio of pixels to supplied metric
# (in this case, inches)
if pixelsPerMetric is None:
pixelsPerMetric = dB / args["width"]
# compute the size of the object
dimA = dA / pixelsPerMetric
dimB = dB / pixelsPerMetric
# draw the object sizes on the image
cv2.putText(orig, "{:.1f}in".format(dimA),
(int(tltrX - 15), int(tltrY - 10)), cv2.FONT_HERSHEY_SIMPLEX,
0.65, (0, 255, 255), 2)
cv2.putText(orig, "{:.1f}in".format(dimB),
(int(trbrX + 10), int(trbrY)), cv2.FONT_HERSHEY_SIMPLEX,
0.65, (0, 255, 255), 2)
contourLength = cv2.arcLength(c,False)
cv2.putText(orig, str(contourLength),
(int(50 + 10), int(50)), cv2.FONT_HERSHEY_SIMPLEX,
0.65, (0, 255, 255), 2)
# show the output image
cv2.imshow("Image", orig)
cv2.waitKey(0)
↧
This encoder requires using the avcodec_send_frame() API
Using opevcv 3.3.x dev from source (Ubuntu 16.04 on ARM) and I get "This encoder requires using the avcodec_send_frame() API" trying to use video writer with and h264 codec. Looking at the source for libav it appears to expect and audio component:
1270 int attribute_align_arg avcodec_encode_audio2(AVCodecContext *avctx,
1271 AVPacket *avpkt,
1272 const AVFrame *frame,
1273 int *got_packet_ptr)
1274 {
1275 AVFrame tmp;
1276 AVFrame *padded_frame = NULL;
1277 int ret;
1278 int user_packet = !!avpkt->data;
1279
1280 *got_packet_ptr = 0;
1281
1282 if (!avctx->codec->encode2) {
1283 av_log(avctx, AV_LOG_ERROR, "This encoder requires using the avcodec_send_frame() API.\n");
1284 return AVERROR(ENOSYS);
1285 }
Not sure if this is a libav issue of opencv issue. If I switch codec to MPEG it works fine. I'm also seeing issues with video capture using H264.
I rolled back to the build I did in May and no problems. Will try Ubuntu upgrade first, then build of OpenCV from source.
↧
Barcode recognition, Sobel derivatives and image transformation problem!
First of all, I am developing a program for barcode reading.I use Sobel derivatives to obtain Gradient representation of image in x and y direction for barcode bars.It works very well in both directions(0 to 270 degree).
But unfortunately Sobel derivative representation can not recognize another angle of the image.I don't know how to explain it, but you can understand it by looking at the two different pictures I've added below.
**Correctly recognized barcode bars,**

**Can not detect from the same angle in reverse view,**

Here is my code for sobel derivatives , I have added y direction gradient view to x direction using addweighted command.
>
vector sobel_variables(1);
sobel_variables[0].alpha = 1;
sobel_variables[0].beta = 0.9;
Sobel(gray_image, sobel_variables[0].Gradx, sobel_variables[0].ddepth, 1, 0, 3);
Sobel(gray_image, sobel_variables[0].Grady, sobel_variables[0].ddepth, 0, 1, 3);
subtract(sobel_variables[0].Gradx, sobel_variables[0].Grady, sobel_variables[0].Gradient);
convertScaleAbs(sobel_variables[0].Gradient, sobel_variables[0].Gradient);
subtract(sobel_variables[0].Grady, sobel_variables[0].Gradx, sobel_variables[0].Gradient1);
convertScaleAbs(sobel_variables[0].Gradient1, sobel_variables[0].Gradient1);
addWeighted(sobel_variables[0].Gradient, sobel_variables[0].alpha, sobel_variables[0].Gradient1, sobel_variables[0].beta, 0, sobel_variables[0].Out_Image);
//sobel_variables[0].Out_Image.
imshow("Sobel_operations", sobel_variables[0].Out_Image);
return sobel_variables[0].Out_Image;
It is really strange.Any help will be apreciated to solve this problem.
↧
how to download install 'createLBPHFaceRecognizer' module opencv raspberry pi
how to download install 'createLBPHFaceRecognizer' module opencv raspberry pi.
i am getting the error
recognizer = cv2.createLBPHFaceRecognizer()
AttributeError: 'module' object has no attribute 'createLBPHFaceRecognizer'
i have tryed sudo apt-get install python-opencv but it say that i have the newest version. no updates could be found.
python-opencv is already the newest version (2.4.9.1+dfsg1-2).
i need help.
↧
↧
ANN_MLP output value error
When I try to train the network to output values to be 1, it gives me an error saying that "OpenCV Error: One of arguments' values is out of range (Some of new output training vector components run exceed the original range too much)".
My code is listed below. Near the end of the code I assign the value of 0.9 and it works. When I switch those values to 1.0, it fails. Thanks for any help you can provide.
#include
using namespace cv;
#pragma comment(lib, "opencv_world331.lib")
#include
#include
using namespace cv;
using namespace ml;
using namespace std;
void add_noise(Mat &mat, float scale)
{
for (int j = 0; j < mat.rows; j++)
{
for (int i = 0; i < mat.cols; i++)
{
float noise = static_cast(rand() % 256);
noise /= 255.0f;
mat.at(j, i) = (mat.at(j, i) + noise*scale) / (1.0f + scale);
if (mat.at(j, i) < 0)
mat.at(j, i) = 0;
else if (mat.at(j, i) > 1)
mat.at(j, i) = 1;
}
}
}
int main(void)
{
const int image_width = 64;
const int image_height = 64;
Mat dove = imread("dove.png", IMREAD_GRAYSCALE);
Mat flowers = imread("flowers.png", IMREAD_GRAYSCALE);
Mat peacock = imread("peacock.png", IMREAD_GRAYSCALE);
Mat statue = imread("statue.png", IMREAD_GRAYSCALE);
dove = dove.reshape(0, 1);
flowers = flowers.reshape(0, 1);
peacock = peacock.reshape(0, 1);
statue = statue.reshape(0, 1);
Mat flt_dove(dove.rows, dove.cols, CV_32FC1);
for (int j = 0; j < dove.rows; j++)
for (int i = 0; i < dove.cols; i++)
flt_dove.at(j, i) = dove.at(j, i) / 255.0f;
Mat flt_flowers(flowers.rows, flowers.cols, CV_32FC1);
for (int j = 0; j < flowers.rows; j++)
for (int i = 0; i < flowers.cols; i++)
flt_flowers.at(j, i) = flowers.at(j, i) / 255.0f;
Mat flt_peacock(peacock.rows, peacock.cols, CV_32FC1);
for (int j = 0; j < peacock.rows; j++)
for (int i = 0; i < peacock.cols; i++)
flt_peacock.at(j, i) = peacock.at(j, i) / 255.0f;
Mat flt_statue = Mat(statue.rows, statue.cols, CV_32FC1);
for (int j = 0; j < statue.rows; j++)
for (int i = 0; i < statue.cols; i++)
flt_statue.at(j, i) = statue.at(j, i) / 255.0f;
const int num_input_neurons = dove.cols;
const int num_output_neurons = 2;
const int num_hidden_neurons = static_cast(sqrtf(image_width*image_height*num_output_neurons));
Mat output_training_data = Mat(1, 2, CV_32F).clone();
Ptr mlp = ANN_MLP::create();
mlp->setBackpropMomentumScale(0.1);
Mat layersSize = Mat(3, 1, CV_16U);
layersSize.row(0) = Scalar(num_input_neurons);
layersSize.row(1) = Scalar(num_hidden_neurons);
layersSize.row(2) = Scalar(num_output_neurons);
mlp->setLayerSizes(layersSize);
mlp->setActivationFunction(ANN_MLP::ActivationFunctions::SIGMOID_SYM);
TermCriteria termCrit = TermCriteria(TermCriteria::Type::COUNT + TermCriteria::Type::EPS, 1, 0.000001);
mlp->setTermCriteria(termCrit);
mlp->setTrainMethod(ANN_MLP::TrainingMethods::BACKPROP);
output_training_data.at(0, 0) = 0;
output_training_data.at(0, 1) = 0;
Ptr trainingData = TrainData::create(flt_dove, SampleTypes::ROW_SAMPLE, output_training_data);
mlp->train(trainingData);
for (int i = 0; i < 1000; i++)
{
if (i % 100 == 0)
cout << i << endl;
Mat flt_dove_noise = flt_dove.clone();
Mat flt_flowers_noise = flt_flowers.clone();
Mat flt_peacock_noise = flt_peacock.clone();
Mat flt_statue_noise = flt_statue.clone();
add_noise(flt_dove_noise, 0.1f);
add_noise(flt_flowers_noise, 0.1f);
add_noise(flt_peacock_noise, 0.1f);
add_noise(flt_statue_noise, 0.1f);
output_training_data.at(0, 0) = 0;
output_training_data.at(0, 1) = 0;
trainingData = TrainData::create(flt_dove_noise, SampleTypes::ROW_SAMPLE, output_training_data);
mlp->train(trainingData, ANN_MLP::TrainFlags::UPDATE_WEIGHTS);
output_training_data.at(0, 0) = 0;
output_training_data.at(0, 1) = 0.9f;
trainingData = TrainData::create(flt_flowers_noise, SampleTypes::ROW_SAMPLE, output_training_data);
mlp->train(trainingData, ANN_MLP::TrainFlags::UPDATE_WEIGHTS);
output_training_data.at(0, 0) = 0.9f;
output_training_data.at(0, 1) = 0;
trainingData = TrainData::create(flt_peacock_noise, SampleTypes::ROW_SAMPLE, output_training_data);
mlp->train(trainingData, ANN_MLP::TrainFlags::UPDATE_WEIGHTS);
output_training_data.at(0, 0) = 0.9f;
output_training_data.at(0, 1) = 0.9f;
trainingData = TrainData::create(flt_statue_noise, SampleTypes::ROW_SAMPLE, output_training_data);
mlp->train(trainingData, ANN_MLP::TrainFlags::UPDATE_WEIGHTS);
}
return 0;
}
↧
Trained haar cascade detection is not working
Hi
I have trained cascade file with 257 positive logos images (png and jpeg format) and 3000 negative images ([reference used](https://github.com/spmallick/opencv-haar-classifier-training)), after 19 stages I collect the cascade file to run some test but this detection method is not giving me accurate result
tested in following systems:
windows pc with opencv '3.2.0'
ubuntu with opencv '2.4.9.1'
Thanks
↧
Detecting pattern in an image
I want to detect a repeating pattern in an image.
So far I detected the contours for each individual object, separated each of the objects by their contours, ending up with a vector of objects of type A, a vector of objects of type B and so on.
Next I tried getting the pattern by extracting the object with the biggest area, putting it in a rectangle, next selecting one object of each kind which is positioned the closest to the current rectangle. After finding a new object, the rectangle would be resized, covering the new object too. In the end, after going through every type of objects and selecting the closest one to the current rectangle from each, I would end up with a rectangle inside which I would have the pattern found in the image.

Well, the problem with the method described is that in a pattern image we can have parts of an object at the sides of the image, and I would end up detecting them as a whole new type of object.
As the method described would try to get one of each type of objects inside a rectangle, I end up with a rectangle with the size of the image.
My questions here is, how could I detect a part of an object A, therefore not detecting it as a new type of an object?
Also, could the hierarchy returned by the findContours be used in detecting the pattern from an image?
In case anyone has any idea of how I could detect a pattern in an image or is aware of some research paper related to the subject, I would appreciate if you would share it with me.
↧