i'm trying to normalize an image. it isn't working. the pixel values are staying the same. help?
img = cv2.imread('image.jpg', 0)
norm_img = np.zeros((800,800))
final_img = cv2.normalize(img, norm_img, 0, 255, cv2.NORM_MINMAX)
the pixel values of img and final_img are unchanged. why?
↧
normalization not working
↧
Evaluate the score of template matching when template's size equals image's size
Hello,
CONTEXT: I am doing a bit of image analysis for the project I am working on and I would like to identify some areas in my image. In those areas, are symbols I need later on so I want to find the black rectangles' positions for later use. Currently I have the black rectangle image and the mask to remove the interior parts of the pattern. I list all the contours of the image. For each contour I check if the size is approximately what I am looking for, if it matches I crop the original image using the contour rect, resize this crop to the template size and match the two. If the score from the match is suitable I accept it and add this contour to the list of black rectangles.
ISSUE: My problem is with the scores. I first struggle to determines what would be an appropriate threshold. When you have template size < image size, you get the best point, but in my case I get a score that is not directly apparently good/bad. Currently I am exploring SQDIFF, and so my idea was to make the worst (highest) score and us that as a scale (0 to worst) to judge my matches. For that worst score I did the following :
Mat imageWorstChannel = imageChannel.clone();
for (int i = 0; i < imageWorstChannel.rows; i++) {
Vec3b tempVec3b;
for (int j = 0; j < imageWorstChannel.cols; j++) {
tempVec3b = imageWorstChannel.at(i, j);
if(tempVec3b.val[0] < 177) tempVec3b.val[0] = 255 - tempVec3b.val[0];
else tempVec3b.val[0] = tempVec3b.val[0];
if (tempVec3b.val[1] < 177) tempVec3b.val[1] = 255 - tempVec3b.val[1];
else tempVec3b.val[1] = tempVec3b.val[1];
if (tempVec3b.val[2] < 177) tempVec3b.val[2] = 255 - tempVec3b.val[2];
else tempVec3b.val[2] = tempVec3b.val[2];
imageWorstChannel.at(i, j) = tempVec3b;
}
}
My problem is I gets some matche's scores above this supposedly "worst" score. Is there maybe something that I misunderstand on how OpenCV matches stuff? Is it the correct way to do what I want ?
ADDITIONNAL INFOS:
- I use imread (..., cv::IMREAD_COLOR) for my template and my image source and imread (..., cv::IMREAD_GRAYSCALE) for my mask
↧
↧
Make Edges of the Image smooth Ask
**I am currently working a simple project**
It is removing the Background of any image and converting it into a Sticker but it is not Giving me Smoother import cv2 import numpy as np from PIL import Image, ImageFilter from google.colab.patches import cv2_imshow from matplotlib import pyplot as pl #img = cv2.imread("/content/police-car-icon-cartoon-style-vector-16884775.jpg") remove_background("/content/WhatsApp Image 2020-08-17 at 1.08.33 AM (2).jpeg") def remove_background(img1): #== Parameters ======================================================================= BLUR = 5 CANNY_THRESH_1 = 10 CANNY_THRESH_2 = 100 MASK_DILATE_ITER = 10 MASK_ERODE_ITER = (1,1) MASK_COLOR = (220,220,220) # In BGR format #== Processing ======================================================================= #-- Read image ----------------------------------------------------------------------- img = cv2.imread(img1) #img = cv2.resize(img, (600,600)) gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #-- Edge detection ------------------------------------------------------------------- edges = cv2.Canny(gray, CANNY_THRESH_1, CANNY_THRESH_2) edges = cv2.dilate(edges, None) ##edges = cv2.erode(edges, None) #-- Find contours in edges, sort by area --------------------------------------------- contour_info = [] contours, _ = cv2.findContours(edges, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE) for c in contours: contour_info.append(( c, cv2.isContourConvex(c), cv2.contourArea(c), )) contour_info = sorted(contour_info, key=lambda c: c[2], reverse=True) #-- Create empty mask, draw filled polygon on it corresponding to largest contour ---- # Mask is black, polygon is white mask = np.zeros(edges.shape) for c in contour_info: cv2.fillConvexPoly(mask, c[0], (255)) # cv2.fillConvexPoly(mask, max_contour[0], (255)) #-- Smooth mask, then blur it -------------------------------------------------------- mask = cv2.dilate(mask, None, iterations=MASK_DILATE_ITER) mask_stack = np.dstack([mask]*3) # Create 3-channel alpha mask mask_u8 = np.array(mask,np.uint8) back = np.zeros(mask.shape,np.uint8) back[mask_u8 == 0] = 255 border = cv2.Canny(mask_u8, CANNY_THRESH_1, CANNY_THRESH_2) border = cv2.dilate(border, None, iterations=3) masked = mask_stack * img # Blend masked = (masked * 255).astype('uint8') # background Colors (blue,green,red) masked[:,:,0][back == 255] = 190 masked[:,:,1][back == 255] = 190 masked[:,:,2][back == 255] = 190 cv2.imwrite('img.png', masked) cv2_imshow( masked) cv2.waitKey(0) cv2.destroyAllWindows() ![Working on this Image][1]
This is the Output Image
![][2] But I want this image to be little smoother like this ![][3] [1]:https://i.stack.imgur.com/E1h9p.jpg [2]:https://i.stack.imgur.com/IiHsZ.jpg [3]:https://i.stack.imgur.com/SnW71.jpg
It is removing the Background of any image and converting it into a Sticker but it is not Giving me Smoother import cv2 import numpy as np from PIL import Image, ImageFilter from google.colab.patches import cv2_imshow from matplotlib import pyplot as pl #img = cv2.imread("/content/police-car-icon-cartoon-style-vector-16884775.jpg") remove_background("/content/WhatsApp Image 2020-08-17 at 1.08.33 AM (2).jpeg") def remove_background(img1): #== Parameters ======================================================================= BLUR = 5 CANNY_THRESH_1 = 10 CANNY_THRESH_2 = 100 MASK_DILATE_ITER = 10 MASK_ERODE_ITER = (1,1) MASK_COLOR = (220,220,220) # In BGR format #== Processing ======================================================================= #-- Read image ----------------------------------------------------------------------- img = cv2.imread(img1) #img = cv2.resize(img, (600,600)) gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #-- Edge detection ------------------------------------------------------------------- edges = cv2.Canny(gray, CANNY_THRESH_1, CANNY_THRESH_2) edges = cv2.dilate(edges, None) ##edges = cv2.erode(edges, None) #-- Find contours in edges, sort by area --------------------------------------------- contour_info = [] contours, _ = cv2.findContours(edges, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE) for c in contours: contour_info.append(( c, cv2.isContourConvex(c), cv2.contourArea(c), )) contour_info = sorted(contour_info, key=lambda c: c[2], reverse=True) #-- Create empty mask, draw filled polygon on it corresponding to largest contour ---- # Mask is black, polygon is white mask = np.zeros(edges.shape) for c in contour_info: cv2.fillConvexPoly(mask, c[0], (255)) # cv2.fillConvexPoly(mask, max_contour[0], (255)) #-- Smooth mask, then blur it -------------------------------------------------------- mask = cv2.dilate(mask, None, iterations=MASK_DILATE_ITER) mask_stack = np.dstack([mask]*3) # Create 3-channel alpha mask mask_u8 = np.array(mask,np.uint8) back = np.zeros(mask.shape,np.uint8) back[mask_u8 == 0] = 255 border = cv2.Canny(mask_u8, CANNY_THRESH_1, CANNY_THRESH_2) border = cv2.dilate(border, None, iterations=3) masked = mask_stack * img # Blend masked = (masked * 255).astype('uint8') # background Colors (blue,green,red) masked[:,:,0][back == 255] = 190 masked[:,:,1][back == 255] = 190 masked[:,:,2][back == 255] = 190 cv2.imwrite('img.png', masked) cv2_imshow( masked) cv2.waitKey(0) cv2.destroyAllWindows() ![Working on this Image][1]
This is the Output Image
![][2] But I want this image to be little smoother like this ![][3] [1]:https://i.stack.imgur.com/E1h9p.jpg [2]:https://i.stack.imgur.com/IiHsZ.jpg [3]:https://i.stack.imgur.com/SnW71.jpg
↧
Help with people detection and tracking
Hi I was following the example in this video
https://www.youtube.com/watch?v=BCJYorKIlN8&t=78s. To build the code in this example I need OpenCV 3.4.1 tracking.hpp which I understand can be found at https://github.com/opencv/opencv_contrib/tree/3.4.10 I was using this tutorial to combine the two https://www.youtube.com/watch?v=_fqpYLM6SCw&t=622s adding tracking to the final cmake file. This seems to work fine and building the output of the cmake file seems to go without a hitch, but when I build the code here https://www.youtube.com/watch?v=BCJYorKIlN8&t=78s I am getting a bunch of LNK2019 and LNK2001 errors. I am not sure how to address these errors and any help would be appreciated.
Thanks
↧
OpenCV modules 3rd-party dependencies
Hello,
I am relatively new to OpenCV (using 4.3.0) and i am trying to make a tiny version of it for and Android application, with only core, imgproc and imgcodecds module imported so that the library files will be as small as possible.
I managed to include only the relevant modules, the problem is that it still relatively big, especially for x86 and x86_64 cpu architecture and i guess (if my guess is wrong then this post is totally irrelevant :0) it is because of 3rd party libraries that imported along with opencv modules.
My question is how can discover which 3rd party libraries are used for each module? and how can i exclude unused 3rd party libraries to make the final .so file smaller?
↧
↧
Replace Color of Image With Criteria
Hello, I recently started with opencv and i need a color-replacement logic for image processing.
My Images are RGB with transparent background. (I think this is the main reason i struggle)
What i want to do:
- Search for groups that only exist of 0xFFF (White)
- Replace them with 0x000 (Black), but only if the shape has a transparent pixel as a neighbour.
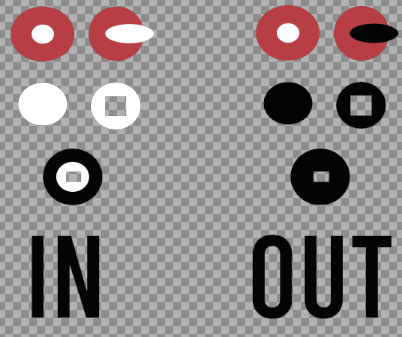
I tried working with connectedComponentsWithStats but the problem is it does not work with rgb + transparent images.
Does anyone have an idea and a hint for me how I could start?
Which methods/algorithms do you recommend for me?
I'm thankful for any kind of help!
Cheers
Stefan
↧
how to calculate VARI using open cv ?
I try to calculate VARI (false-NDVI) in visual studio and coding like below but the result is not what I want
split(img, chanel); //split rgb to 3 bands
Mat vari = (chanel[1] - chanel[2]) / (chanel[1] + chanel[2] - chanel[0]);
↧
"GNU Radio" like GUI/Distro for OpenCV
It's a little "meta" - but I've been thinking about doing something like GNU Radio but for OpenCV - i.e. "drag and drop" blocks and modules that you can graphically connect together to connect sources, "sinks", (inputs/output) complete with intermediate graphs, filters, etc.
Are there any efforts like this out there already? It seems like a natural fit - so I don't want to re-invent the wheel...
↧
request help,Status -43: CL_INVALID_BUILD_OPTIONS
compile opencv-4.4.0, opencv_contrib-4.4.0 with opencl enable
cmake_vars = dict(
CMAKE_TOOLCHAIN_FILE=self.get_toolchain_file(),
CMAKE_BUILD_TYPE="Debug",
INSTALL_CREATE_DISTRIB="ON",
WITH_OPENCL="ON",
OPENCL_FOUND="ON",
OPENCV_DNN_OPENCL="ON",
WITH_IPP=("ON" if abi.haveIPP() else "OFF"),
WITH_TBB="ON",
BUILD_EXAMPLES="OFF",
BUILD_TESTS="OFF",
BUILD_PERF_TESTS="OFF",
BUILD_DOCS="OFF",
BUILD_ANDROID_EXAMPLES=("OFF" if self.no_samples_build else "ON"),
INSTALL_ANDROID_EXAMPLES=("OFF" if self.no_samples_build else "ON"),
BUILD_ANDROID_PROJECTS="OFF",
OPENCL_INCLUDE_DIRS="**********/Adreno_OpenCL_SDK/opencl-sdk-1.2.2/inc/CL",
OPENCL_LIBRARY="*************/Adreno_OpenCL_SDK/system_lib64/libOpenCL.so"
**when call function net.forward(outs, outNames); An error occurred :Status -43: CL_INVALID_BUILD_OPTIONS**
----------
OpenCV(ocl4dnn): consider to specify kernel configuration cache directory
via OPENCV_OCL4DNN_CONFIG_PATH parameter.
[ INFO:0] global /home/hyq/opencv4.4.0/opencv-4.4.0/modules/core/src/ocl.cpp (356) OpenCLBinaryCacheConfigurator Specify OPENCV_OPENCL_CACHE_DIR configuration parameter to enable OpenCL cache
OpenCL program build log: dnn/dummy
Status -43: CL_INVALID_BUILD_OPTIONS
-cl-no-subgroup-ifp
Unsupported OpenCL user option specified: '-cl-no-subgroup-ifp'
↧
↧
Cutting selected frame ranges from a video
I am quite new to OpenCV and would like to know what is the best approach to cut selected ranges of frames from a video-file. Say for example you have a video-file VideoIn.avi with 10000 frames, and you want to extract frames 100->500 into output video VideoOut1.avi, and frames 7000->8000 into output video VideoOut2.avi. What would be the best approach using OpenCV?
↧
How do i pipeline the object detection module output to the input of my tracking algorithm?
Hi, i am trying to use OpenCV for counting things like vehicles or people. I am planning on using canny edge detector for object detection, followed by tracking(maybe CSRT or something). How do i setup a pipeline for that? The examples on tracking online seem to do a manual ROIs to track objects. However, i want to apply object detection and let my tracker auto detect the ROIs.
↧
Error in BFMatcher : batch_distance
hi i wrote these codes for detect corner features using Shi-Tomasi and used Bruteforce Matcher for Match features between two images.
cap = cv2.imread('mario.png', 0)
model = cv2.imread('mario 3d.jpg', 0)
corners1 = cv2.goodFeaturesToTrack(cap, 20, 0.01, 10)
corners2 = cv2.goodFeaturesToTrack(model, 20, 0.01, 10)
corner1 = np.int0(corners1)
corner2 = np.int0(corners2)
bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=False)
matches = bf.match(corners1, corners2)
but Pycharm 2020 gives this Error:
matches = bf.match(corners1, corners2)
cv2.error: OpenCV(4.4.0) C:\Users\appveyor\AppData\Local\Temp\1\pip-req-build-cff9bdsm\opencv\modules\core\src\batch_distance.cpp:275: error: (-215:Assertion failed) type == src2.type() && src1.cols == src2.cols && (type == CV_32F || type == CV_8U) in function 'cv::batchDistance'
I used Python 3 and Opencv-python 4.4.0.42 and Opencv-contrib-python with Same Version exactly
Please Help me How to fix it?
↧
How to store CV_16UC1 image on hard disk?
Hi,
Could someone please let me know how can I store CV_16UC1 image using opencv? Is there a function which can be used?
One way is, covert the image to CV_8UC1 and store it on hard disk using cv::imwrite() function. But doing that will result in loss of information. Hence, I do not want to convert the image.
In my case, I have depth image available from kinect v2 and I want to store it on hard disk.
Thank you!
↧
↧
How to check matching location\position(SIFT)?
Hey, I am working on fingerprint recognition.
I am using SIFT to find minutiae points but I want not only to find the minutiae points I want to check if they are in the same place or region in both photos.
my code is:
sift = cv.SIFT_create()
keypoints_1, descriptors_1 = sift.detectAndCompute(img1,None)
keypoints_2, descriptors_2 = sift.detectAndCompute(img2,None)
bf = cv.BFMatcher(cv.NORM_L1, crossCheck=True)
matches = bf.match(descriptors_1,descriptors_2)
matches = sorted(matches, key = lambda x:x.distance)
img3 = cv.drawMatches(img1, keypoints_1, img2, keypoints_2, matches[:3], img2, flags=2)
plt.imshow(img3),plt.show()
print(len(matches))
with this code I can detect two simillar minutiae points but they can be in different positions and thats is my problem.
↧
Gabor filter parameters.
Hey I am working on fingerprint project.
I am implementing method from : https://answers.opencv.org/question/6364/fingerprint-matching-in-mobile-devices-android-platform/
in python open-CV.
In the gabor filer stage I am doing this:
g_kernel = cv.getGaborKernel( ... )
gabor_filtered = cv.filter2D(equ, cv.CV_8UC3, g_kernel)
but I dont know what parameters to enter in getGaborkernel to get to the same result as in the article I posted link before.
↧
OpenCL Support for QUALCOMM GPU
Hai ,
Does OpenCV OpenCL(cv::ocl) supports QUALCOMM GPU? In ocl.cpp source code , there are 4 vendor IDs (3 for Intel,AMD & Nvidia and 1 for UNKNOWN_VENDOR). Does OpenCV OpenCL supports other GPUs(Mobile GPUs).? If so How to check that?
What happens if Vendor is set to UNKNOWN_VENDOR?
↧
error in using cvtColor
hi i want convert color images to gray with cvtColor function, but i wrote below code:
gray_img1 = cv2.cvtColor(cap, cv2.COLOR_BGR2GRAY)
and pycharm gives this error:
cv2.error: OpenCV(4.4.0) c:\users\appveyor\appdata\local\temp\1\pip-req-build-
cff9bdsm\opencv\modules\imgproc\src\color.simd_helpers.hpp:92: error: (-2:Unspecified error) in function '__thiscall
cv::impl::`anonymous-namespace'::CvtHelper,struct
cv::impl::A0x8d73748c::Set<1,-1,-1>,struct cv::impl::A0x8d73748c::Set<0,2,5>,2>::CvtHelper(const class cv::_InputArray
**Invalid number of channels in input image:**
> 'VScn::contains(scn)'> where> 'scn' is 1
Please help me to fix this error completely.
↧
↧
CUDACuts for Image Texture Synthesis
I am doing a project requiring composing full 360-degree view images. To produce an output image with no visible seam, I adopted the GraphCut algorithm on paper "Graphcut Textures: Image and Video Synthesis Using Graph Cuts" which based on the maxflow/min-cut algorithm. I used the implementation in CPU of Kolmogorov and Boykov described in the paper"An Experimental Comparison of Min-Cut/Max-Flow Algorithms for Energy Minimization in Vision" to find the best min-cut to stitch image which gives rise to a relatively good result.
However, I want a faster implementation to solve the maxflow/min-cut algorithm. That when I found an implementation on CUDA described in "CudaCuts: Fast Graph Cuts on the GPU". I successfully run their examples on their project page on image segmentation and produce the same results as they did. However, when I apply it to my problem, it did not work properly. The only difference in the 2 problems is the way I construct the graph representation for the maxflow/min-cut algorithm to solve. I constructed the graph as they suggested in "Graphcut Textures: Image and Video Synthesis Using Graph Cuts" in which the terminal weights(t-links) are infinite for valid source(sink) nodes and 0 otherwise and neighbor weights(n-links) corresponding to a cost function in paper. That graph representation worked well with Boykov implementation on CPU but it did not work for CUDA implementation by Vibhav Vineet and Narayanan.
I confused since the CUDA implementation worked well for the image segmentation problem meaning the core algorithm (maxflow/min-cut) was correct. Therefore, I guess I am doing something wrong with graph construction. Could anyone who has done experiments with this CUDA implementation give me a hint? Am I misunderstanding the meaning of dataTerm(terminal weights/t-links), smoothTerm(neighbor weights/ n-links) in their code
↧
How can I detect curved line?

1. How Can I extract curved lines in the following image using Opencv?
2. How to extract only horizontal lines? inside -30 to +30 degrees
I need to detect horizontal lines from the following image including curved lines.
I did like these steps.
Color - Grayscale - GaussianBlur(to remove noise) - CannyEdge - HoughLineP
But I get both of horizontal and vertical lines, and i cannot detect curved lines.
Please help, any Idea
↧
error in findHomography with RANSAC
hi i wrote this codes for estimating Transformation Function between an 2d Image vs 3d Image as:
src_pts = np.float32([kp1[m.queryIdx].pt for m in matches]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in matches]).reshape(-1, 1, 2)
**compute Homography**
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
but pycharm gives many lines of Errors:
*Error: failed to send plot to http://127.0.0.1:63342
urlopen(url, buffer)
return opener.open(url, data, timeout)
response = self._open(req, data)
result = self._call_chain(self.handle_open, protocol, protocol +
result = func(*args)
return self.do_open(http.client.HTTPConnection, req)
r = h.getresponse()
response.begin()
version, status, reason = self._read_status()
line = str(self.fp.readline(_MAXLINE + 1), "iso-8859-1")
return self._sock.recv_into(b)*
**ConnectionResetError: [WinError 10054] An existing connection was forcibly closed by the remote host**
↧